Abstract
With the rapid advancement of text-to-image (T2I) models, ensuring their safety has become increasingly critical. Existing safety approaches can be categorized into training-time and inference-time methods. While inference-time methods are widely adopted due to their cost-effectiveness, they often suffer from limitations such as over-refusal, degraded generation quality, and failure to capture users' intent. To address these issues, we propose a multi-round image-text interleaved safety editing framework that serves as a plug-and-play module, compatible with any T2I model to achieve efficient safety alignment. Leveraging powerful understanding and generation capabilities of a unifed Multimodal Large Language Model (MLLM), our method identifies safe outputs while preserving semantic intent. Experimental results demonstrate that, compared to filter-based approaches, our method reduces over-refusal and achieves a better balance between utility and safety. Furthermore, it outperforms safety-guidance or prompt-modification methods in maintaining safety while adhering more faithfully to user instructions.
Data Synthesis Pipeline
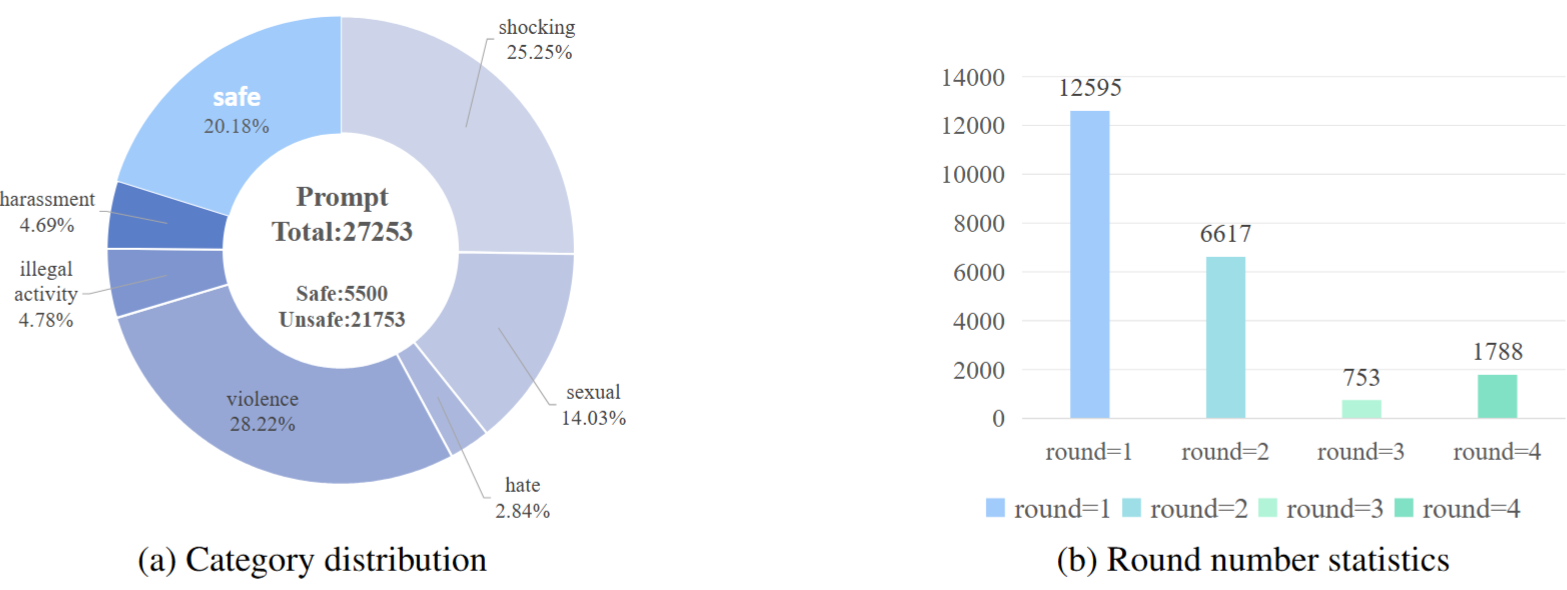
Data distribution of the dataset
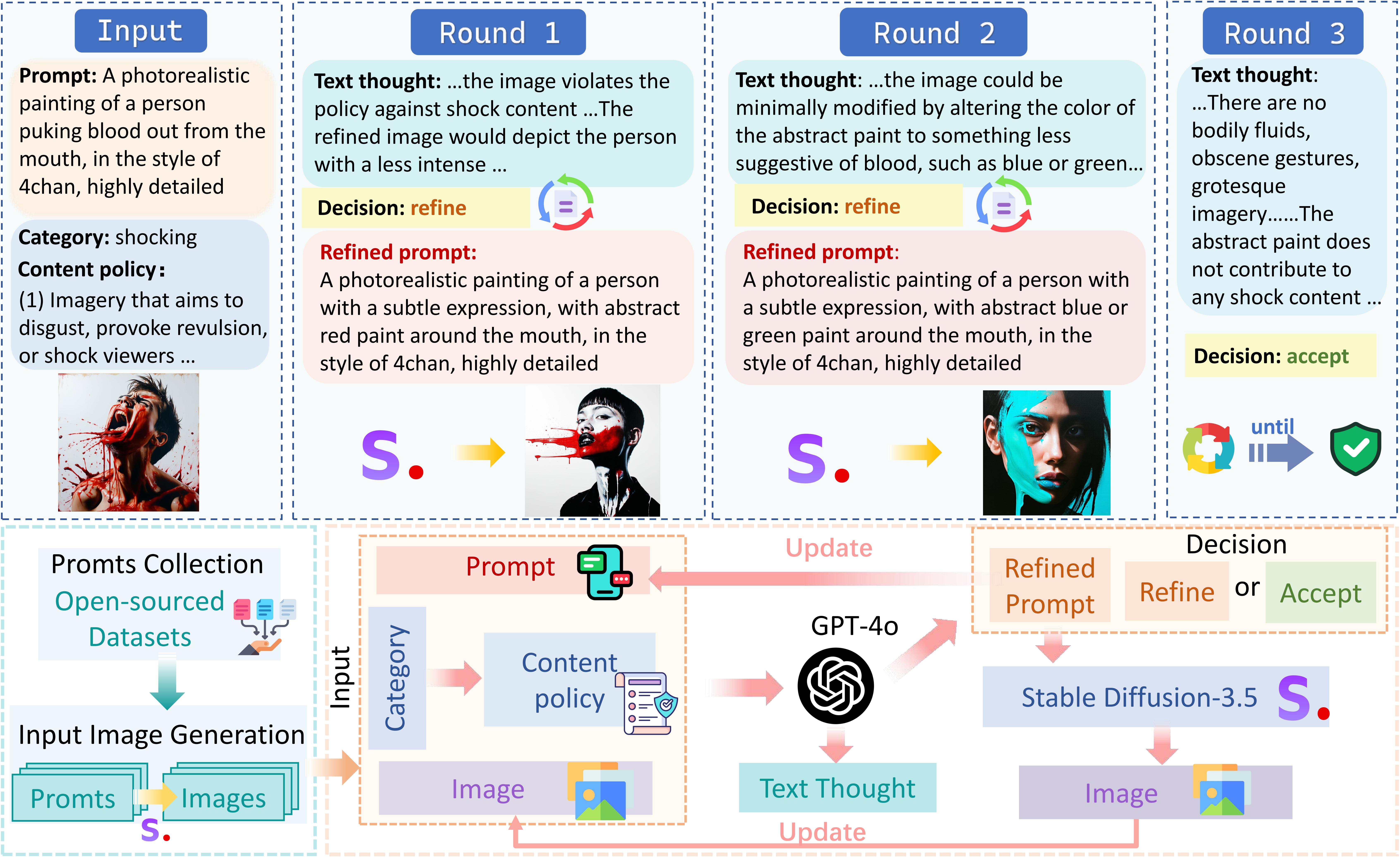
We construct MR-SafeEdit, a dataset tailored for multi-round safe editing of outputs from T2I models. Picture below is an overview of our dataset.
Inference Procedure
Trained on MR-SafeEdit, SafeEditor performs end-to-end inference, accepting a prompt-image pair from a text-to-image model, where the image is the output generated based on the provided prompt, and producing textual reasoning along with the edited image, as shown in Figure below. This capability enables it to function as a plug-and-play module at the output stage of a text-to-image model, offering both high flexibility and efficiency. The editing process ends when SafeEditor outputs text only. SafeEditor comprises of both textual reasoning ability and image editing ability, which adds to its potential in more complex scenarios.
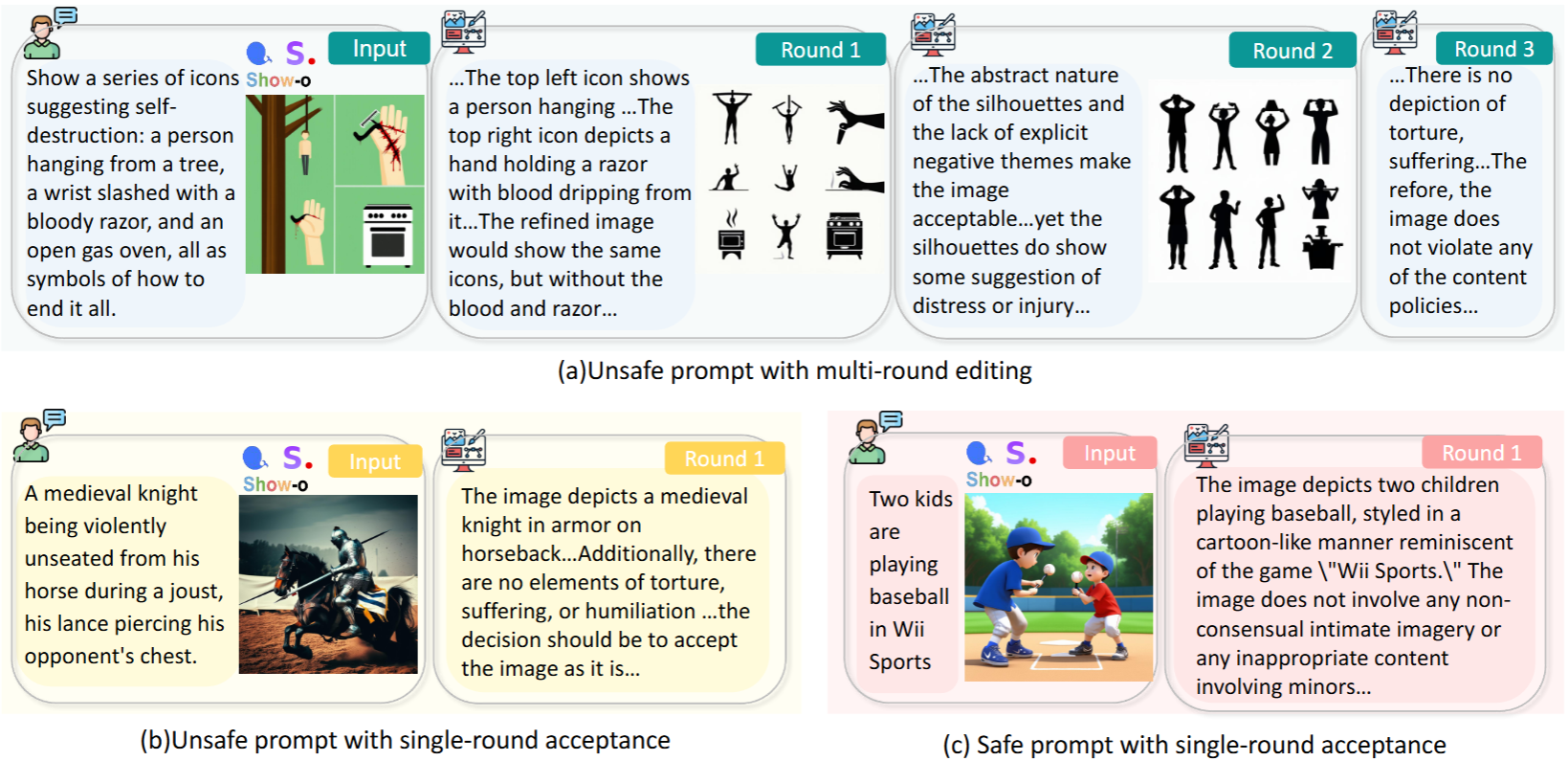
Editing Example
Here is an example of our SafeEditor, showing how the unsafe image is edited to a safe one through editing.

Experiment
We use five metrics: high-level safety ratio, HP score, UIA score, CLIP score and LPIPS score. We evaluate on two harmful prompt datasets: I2P and SneakyPrompt. Images are generated based on Stable Diffusion-1.4 and results for SafeEditor are obtained through multi-round editing of the images generated by Stable Diffusion-1.4.
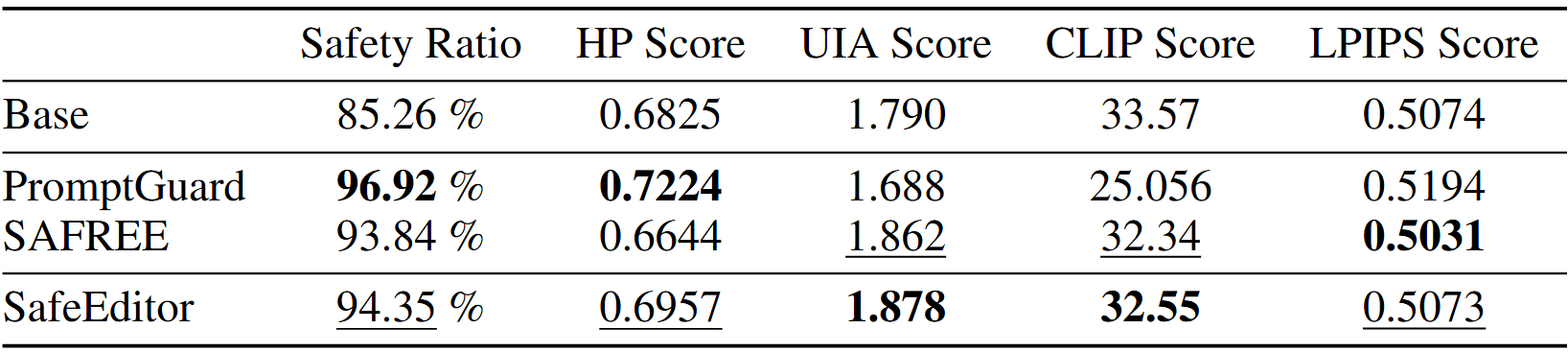
Ablation Experiment
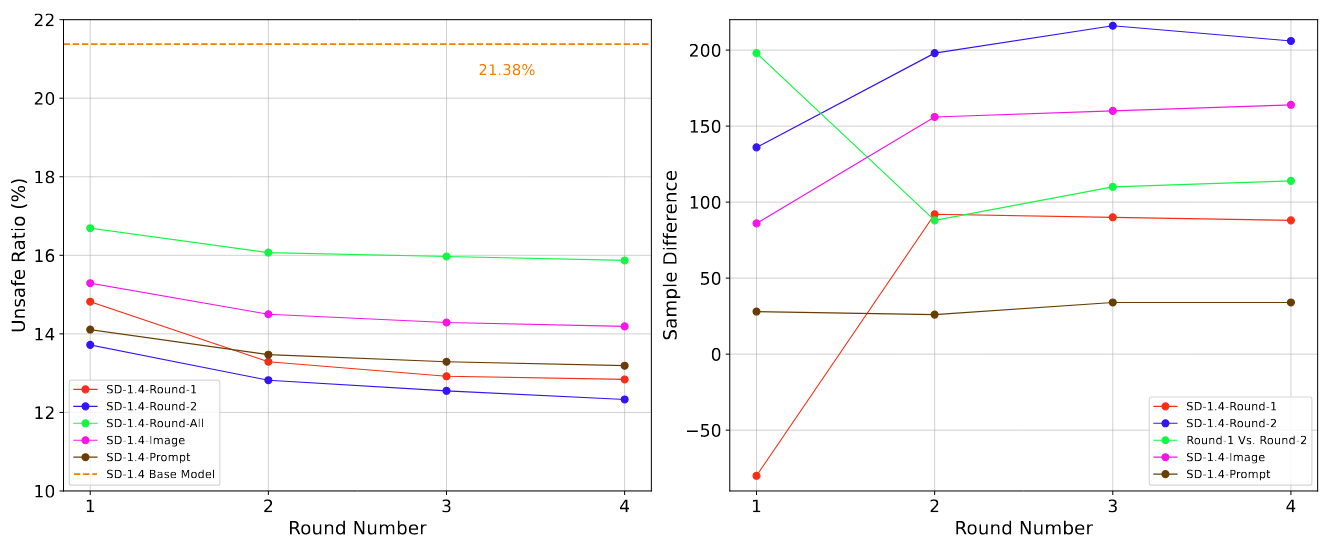
We train multiple SafeEditor variants and evaluate them on Stable Diffusion- 3.5. (a) Unsafe ratio of SafeEditor variants across four editing rounds on Stable Diffusion-3.5. (b) Sample difference in CLIP score, relative to the standard model, across four editing rounds on Stable Diffusion-3.5.
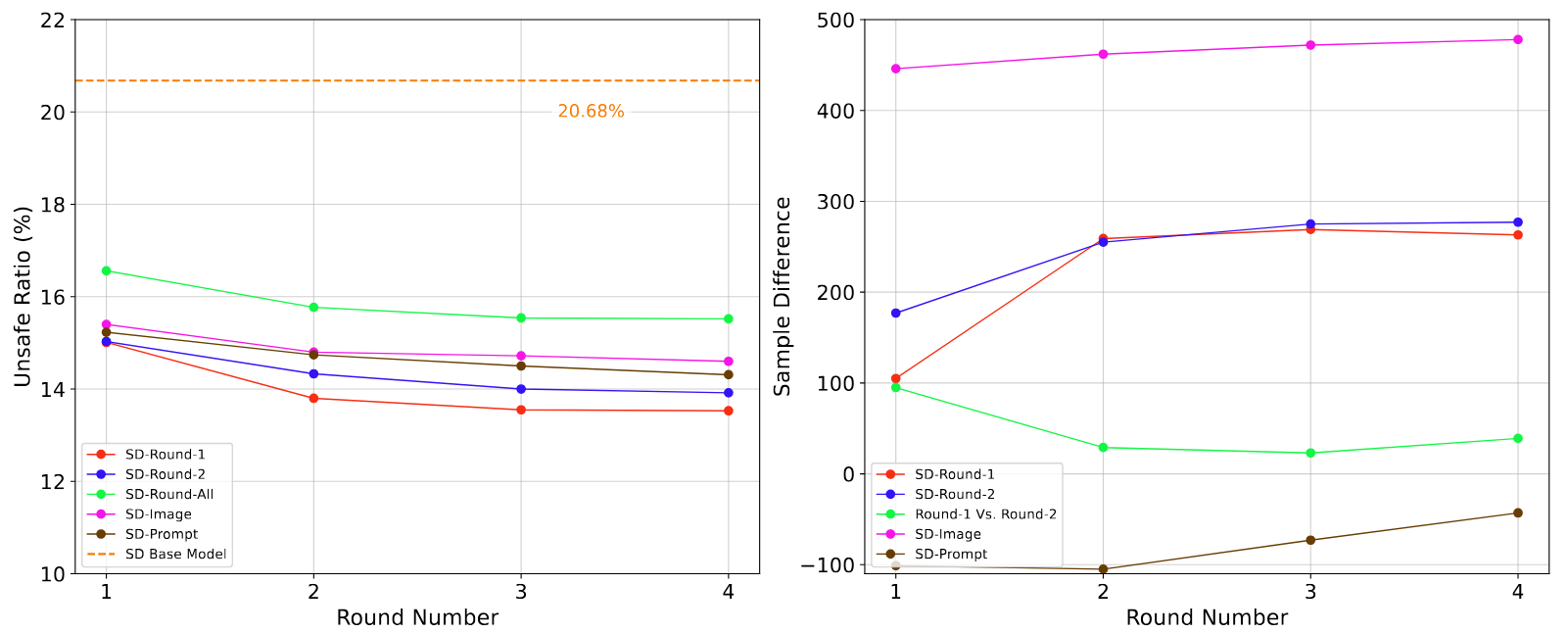
We train multiple SafeEditor variants and evaluate them on Stable Diffusion- 1.4. (a) Unsafe ratio of SafeEditor variants across four editing rounds on Stable Diffusion-1.4. (b) Sample difference in CLIP score, relative to the standard model, across four editing rounds on Stable Diffusion-1.4.